
FSL
Presenta
ESTADISTICA
REGRESION LOGISTICA
MULTIPLES APLICACIONES
medicina, marketing, psicología, ingeniería, ...
ES UTIL CUANDO ...
se desea predecir la presencia o ausencia
de una característica o resultado según
los valores de un conjunto de predictores.

REGRESION
Logística
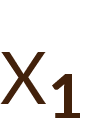
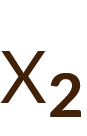
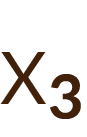



















LA REGRESION LOGISTICA
permite calcular
la probabilidad
de padecer cáncer
en función de unos
factores de riesgo ...
... o también
cuánto aumenta
la probabilidad
por cada kg de sobrepeso
o número de cigarrillos
adicionales fumados
¿Qué es la regresión logística?
Una de las aplicaciones de la estadística es encontrar relaciones entre diferentes variables y cuantificar esa relación mediante una función matemática que nos permita, a partir del conocimiento de una o varias variables (variables independientes o explicativas), predecir el valor de otra variable (variable dependiente). Cuando la variable que deseamos predecir es un atributo que se mide en términos de tener o no tener una determinada cualidad (desarrollar o no una determinada enfermedad, comprar o no un determinado producto, cumplir o no cumplir una obligación de pago) se utiliza lo que se denomina modelo de regresión logística.
¿En qué consistió el proyecto realizado?
Se consideró como variable respuesta (dependiente) «padecer cáncer» (sí o no) y como variables independientes el «número medio de cigarrillos fumados», el «nivel de colesterol» y los «kilogramos adicionales de sobrepeso». Con los datos de estas variables obtenidos para una serie de individuos y utilizando un análisis de regresión logística se obtuvo la probabilidad de sufrir un infarto de miocardio en función de unos valores concretos de los factores de riesgo. También se estimó cuánto aumentaba la probabilidad de sufrir un infarto por cada cigarrillo adicional o por cada kilogramo adicional de sobrepeso que tuviera el individuo.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}